개요
- 개발자는 여러 형태의 조인문 작성해서 실행한다.
- PostgreSQL에서 옵티마이저는 조인이 포함된 쿼리를 보통 아래 3가지 조인 방법 중에서 적절한 조인 방식을 선택한다.
- NL Join (Nested Loop Join)
- Hash Join
- Merge Join
- 따라서, 조인 방법을 이해하는 것은 실행계획을 분석하는데 매우 중요한 부분이다.
필수 사전 지식
테이블 생성
create table team
(
team_id bigint,
team_name varchar(100),
created_at timestamp with time zone
);
create table member
(
member_id bigint,
member_name varchar(100),
team_id integer,
join_date timestamp with time zone
);Nested Loop Join
- 선행 테이블에서 결과를 가져온 후, 그 결과에 대해 후행 테이블의 각 행을 검사하는 방식이다.
- 쉽게 생각하면, 2중 for 문을 생각하면된다.
- NL 조인을 하기위해서는
인덱스가 잘 걸려있는 것이 매우 중요하다. - 인덱스가 없다면, 두 테이블 모두 Full Table Scan 해야하기 때문이다.
- 물론 이런경우에는 옵티마이저가 NL 조인을 선택하지 않을 확률이 매우 높다.
- 정리하면, Nested Loop Join은 반복적으로 쿼리하기 때문에 인덱스가 걸려있지 않다면 다른 조인방식에 비해서 성능이 낮을 수 있다.
- 테스트를 위해서 아래와 같이 데이터를 넣었다.
데이터 세팅
- team 테이블에 만건, member 테이블에 10만건의 데이터를 넣었다.
INSERT INTO team (team_id, team_name, created_at)
SELECT
i,
'Team ' || i,
CURRENT_TIMESTAMP - INTERVAL '1 day' * (i % 365)
FROM generate_series(1, 10000) AS i; -- 1만건
INSERT INTO member (member_id, member_name, team_id, join_date)
SELECT
i,
'Member ' || i,
(i % 10000) + 1, -- team_id를 1부터 10000까지 순환
CURRENT_TIMESTAMP - INTERVAL '1 day' * (i % 365)
FROM generate_series(1, 100000) AS i; -- 10만건
- 이제 각각의 테이블에 인덱스를 설정하고 실행계획을 살펴보자.

- 먼저 옵티마이저가 Nested Loop Join 방식으로 테이블을 조인한걸 확인할 수 있다.
- 또한, 두 테이블을 탐색하는 과정에서 인덱스를 활용한 것도 알 수 있다.
- 즉, NL 조인은
유리한 인덱스가 걸려있을때 좋은 성능을 낼 수 있는 조인 방식이다.

- team에 만건의 데이터를 넣었었다. 따라서
where team.team_id > 9990를 한다면 team 테이블에서 10건이 남는다.- where 절을 넣은 이유는 넣지 않으면 높은 확률로 Hash Join을 사용하기 때문이다.
- 그 이유는 Hash Join이 대용량 처리에 유리하기 때문이다. (이 부분은 아래에서 좀 더 자세히 살펴보자.)
- NL 조인은 마치 2중 for 문과 같다고 했다. 따라서 team 에서 10건이 반환됐다면, 그 다음 테이블은 member 테이블의 loops는 10이 될 것이다.
- 정리해보면, NL 조인은 유리한
인덱스가 잘 걸려있냐에 아주 큰 영향을 받고,소량 데이터를 처리하거나 부분범위 처리를 하는 경우에 주로 사용된다.
Hash Join
- Hash Join은 Build 단계와 Probe 단계를 거쳐 수행된다.
- Build 단계에서는
작은 테이블을 읽어서메모리에해시 테이블을 생성한다. - Probe 단계에서 큰 테이블을 읽어
해시 테이블을 탐색하면서 조회한다. - 조인 조건이
동등 조건일때 주로 사용된다. - NL 조인에 비해서
대용량 데이터 처리에 유리하다.- 특히, 한 테이블이 상대적으로 적고, 다른 한 테이블이 상대적으로 크다면 더욱 효과적이다.
- 그 이유는 위에서 언급했듯이 작은 테이블을 메모리에 올리기 때문이다.
PostgreSQL 에서 해시 테이블은 요청을 처리하는 백엔드 프로세스의
work_mem라는 메모리 공간에 저장된다. 만약, Build 작업을 work_mem 내에서 모두 처리할 수 있다면, 이것을 In-Memory 해시조인 이라고 하며, In-Memory 해시조인으로 동작한다면, 이 경우, 모든 조인 관련 데이터는 한 번에 메모리에 로드되기 때문에 성능적으로 매우 유리하다. 또한, In-Memory 해시조인으로 처리됐다면 Batches 값이1이다. (Batches 값은 아래 실행계획에서 확인할 수 있다.)
- 이제 본격적으로 실행계획을 보자

- 해시조인의 경우,
실행 계획을 읽는 순서가 조금 다르다. - 원래는 같은 레벨의 노드는 위에서 아래로 순차적으로 읽지만, 해시조인의 경우,
Hash 노드부터 읽는다. - 그 이유는 Hash 노드가
Build 단계이고 그 위에 Scan 노드가Probe 단계이기 때문이다.

- Buckets
- 해시 테이블에서 사용되는
버킷의 수를 나타낸다. - 버킷은 해시 테이블 내에서 각각의 고유 해시 값을 저장하는 데 사용되는 슬롯이다.
최솟값은 1024이며, 버킷의 수는 해시 테이블의 충돌을 줄이고 검색 성능을 최적화하는 데 중요한 역할을 한다. 버킷 수가 너무 적으면 해시 충돌이 많아지고, 너무 많으면 메모리 사용량이 증가한다.
- 해시 테이블에서 사용되는
- Batches
- In-Memory 해시 조인으로 처리된 경우, Batches의 값은
1이다. 2이상이라면, In-Memory 해시 조인으로 처리되지 못한것이다. 이는 해시 조인을 위한 데이터가 work_mem 설정을 초과하여 여러 배치로 나뉘어 처리되었음을 나타낸다. 즉, 일부 데이터가 디스크에 임시 저장되어 조인이 여러 단계로 나뉘어 실행된다.- 값이 2라고 가정하면, 전체 데이터를 2개의 별도 배치로 나누어 처리했다는 것을 의미한다.
- In-Memory 해시 조인으로 처리된 경우, Batches의 값은
- Memory Usage
work_mem 사용량을 의미한다.
Merge Join
- Merge Join은
소트 단계와머지 단계를 거쳐 수행된다. - 소트 단계에서
양쪽 집합을 조인 컬럼을 기준으로 정렬하고 머지 단계에서 정렬한양쪽 집합을 서로 머지한다. - 정렬된 결과를 work_mem에 저장한다. 만약 크기가 크면 디스크에서 처리한다.
- NL 조인에 비해서
대용량 데이터를 처리하는데 유리하다. - NL 조인, Hash Join과는 다르게 탐색과정에서
인덱스를 사용하지 않는다. 따라서 인덱스가 없는 경우 선택될 가능성이 높다.- 만약 인덱스가 있다면, 정렬작업을 인덱스를 활용하여 생략할 수 있다.
- 대용량 데이터를 처리해야하지만
조인 조건이 동치(=)가 아닌 경우Hash Join 대신 Merge Join이 선택되기도 한다. - 또한, 조인 조건식이 아예 없는 조인(Cross Join, 카테시안 곱)일 경우에도 자주 선택된다.
- 이미 정렬된 데이터에 대해서 Merge Join 이 선택될 확률이 높다.
- NL 조인의 경우, 유리한 인덱스가 적용되어 있어도 랜덤 I/O는 피할 수 없다. 하지만, Merge Join의 경우는 순차적 I/O를 하기 때문에 대규모 데이터 처리에 유리하다.
- 두 테이블이 정렬되어 있지 않은 경우
사전 정렬 작업이 필요하다. - 먼저, 정렬이 안되어있는 경우에 대해서 살펴보기 위해 인덱스를 삭제하고 실행계획을 보자.

- 대용량 데이터인 경우, 보통 해시조인이 선택되기 때문에
set enable_hashjoin = off;을 통해서 Merge Join을 유도했다. - 정렬이 안되어 있기 때문에, 사전 정렬 단계를 거쳐서 머지하고 있는 것을 확인할 수 있다.
- 이제 정렬이 되어있는 경우를 보자.

- 인덱스에 의해 정렬이 되어있기 때문에 사전 정렬 작업이 생략된 것을 확인할 수 있다.
- 즉, 별도의 정렬 단계 없이 바로 Merge 단계로 넘어간 것이다.
Nested Loop Outer Join
- Inner Join 이 아닌 Outer Join 의 경우에는 NL Outer Join 으로 동작한다.
- NL Join 과 NL Outer Join는 기준 테이블(Driving Table)을 선정하는데 차이가 있다.
- NL Join의 경우, 작은 테이블을 기준 테이블(Driving Table)로 선정한다. 반면, Outer Join은 기준 테이블(from절)로 설정한 테이블을 기준 테이블(Driving Table)로 선정한다.
- team 테이블에는 1만건, member 테이블에는 10만건이 있다고 가정하고 아래 실행계획을 보자.

- 먼저, 기준 테이블을 선정하는 과정을 투명하게 보기 위해서
SET enable_material = OFF를 설정했다. - 위 실행계획에서 볼 수 있듯이, NL Join의 경우에 team, member 중에서 크기가 작은 team을 기준테이블로 선정한 것을 확인할 수 있다.

- left (outer) join의 경우, from 절에서 선택한 기준 테이블을 기준 테이블(Driving Table)로 선택하는 것을 확인할 수 있다.
그렇다면 outer join의 경우에는 옵티마이저가 무조건 NL Outer Join을 선택할까?- 똑똑한 옵티마이저는 당연히 그렇지 않다. 아래의 경우를 보자.
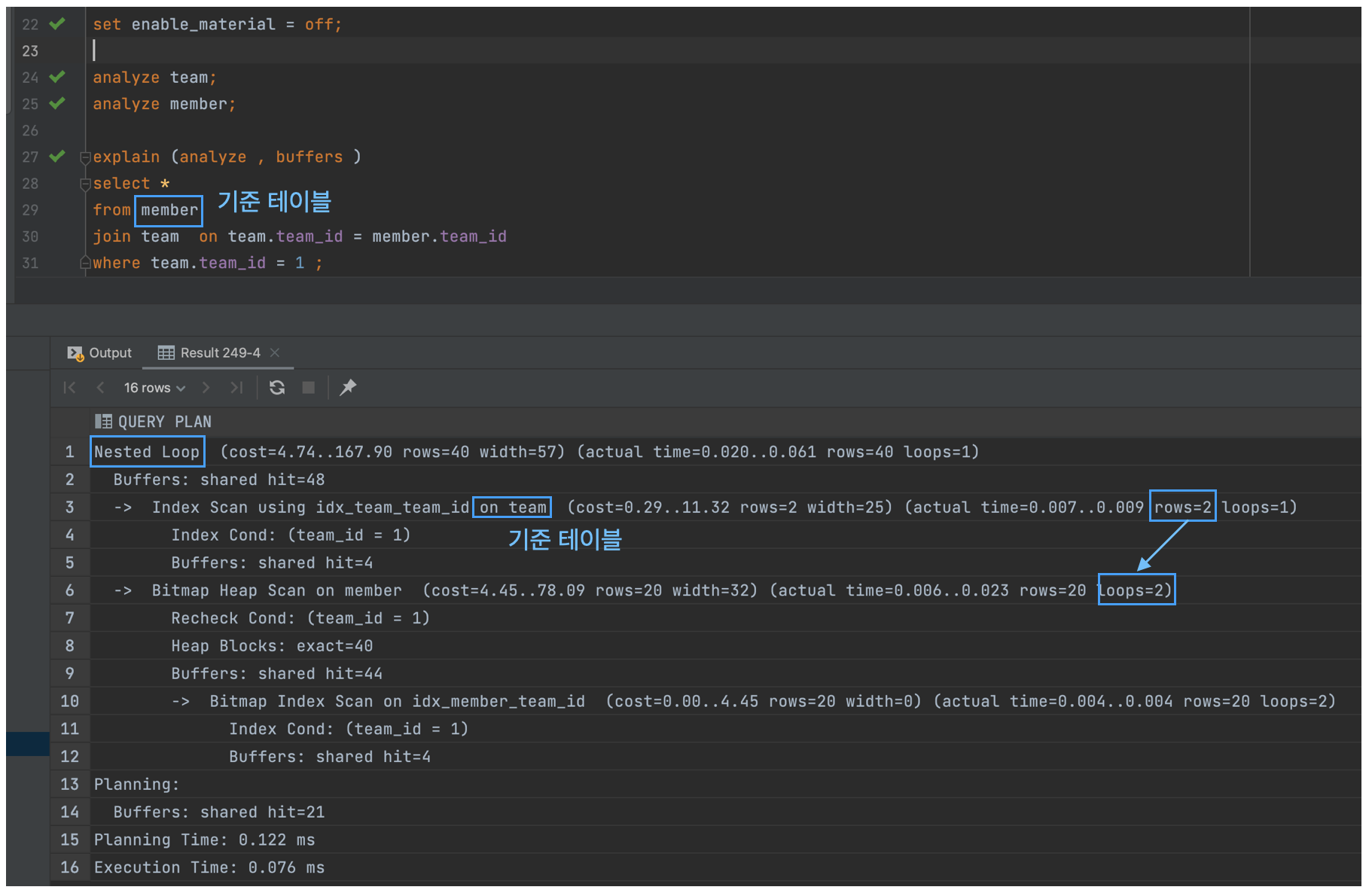
- 바뀐건 where 절에서 member.team_id 를 team.team_id 로 바꾼 것 밖에 없다.
- 그렇다면 왜 옵티마이저는 NL Outer Join이 아닌 NL Join을 선택한 것일까?
- member 테이블을 기준테이블로 설정한 NL Outer Join의 동작방식은 아래와 같다.
- member 테이블의 모든 행과 team 테이블의 매칭되는 행을 반환한다. 즉,
기준 테이블의 데이터는 매칭되지 않아도 반환되어야한다. - where member.team_id 라면 조건이 기준테이블에만 적용되기 때문에
기준 테이블에 매칭되지 않은 데이터가 반환되어야 한다는 룰은 유지해야된다.
- member 테이블의 모든 행과 team 테이블의 매칭되는 행을 반환한다. 즉,
- 하지만 where team.team_id 라면,
기준 테이블에 매칭되지 않은 데이터는 전부 걸러질 것이다. 따라서 NL Outer Join을 유지하는 것은 무의미하다. - 이럴때 옵티마이저는 NL Join을 선택한다.
- 즉,
Outer Join을 할지라도, where 조건절에 따라서 NL Outer Join이 아닌 NL Join이 선택되기도 한다.
Hash Left Join & Hash Right Join
- 이제 Hash Outer Join에 대해서 알아보자
- NL Outer Join의 경우, 기준 테이블(from절)로 설정한 테이블을 기준 테이블(Driving Table)로 선정한다고 언급했다.
- Hash Outer Join의 경우에도 기준 테이블(from절)로 설정한 테이블을 Build Table로 설정할까?
- 그렇지 않다. 그 이유는 Build Table이 클 경우에 성능이 급격히 떨어지기 때문이다.
- 그렇기 때문에 Hash Outer Table의 경우에도 Hash Table과 마찬가지로
작은 테이블을 Build Table로 설정한다. - Hash Left Join 와 Hash Right Join는 아래와 같이 해석하면 된다.
- Hash Left Join:
왼쪽 테이블을 Probe Table로 설정한다. (오른쪽 테이블이 Build Table) - Hash Right Join:
오른쪽 테이블을 Probe Table로 설정한다. (왼쪽 테이블이 Build Table)
- Hash Left Join:
- 이제 실행계획을 살펴보자.

- 위 쿼리에서 왼쪽 테이블이 member, 오른쪽 테이블이 team이다.
- team 테이블이 크기가 적기때문에 team이 Build Table이 되어야 하고, member가 Probe 테이블이 되어야한다.
- 따라서 왼쪽에 있는 member 테이블을 Probe가 되는 Hash Left Join이 선택된다.
- 이번엔 반대로 왼쪽 테이블을 team, 오른쪽 테이블을 member로 설정하고 실행계획을 살펴보자.
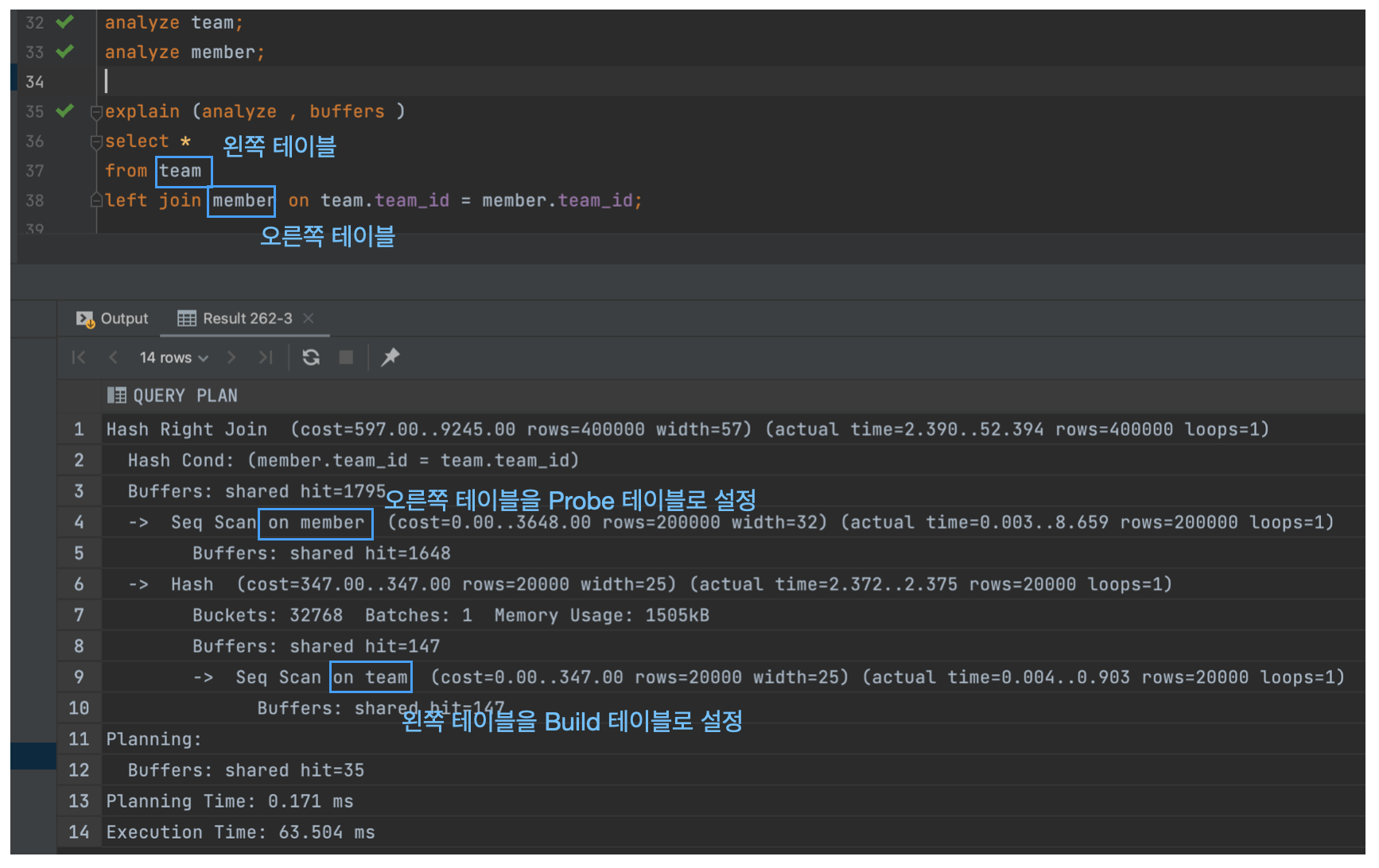
- 이번에는 오른쪽에 있는 member 테이블이 Probe 테이블이 되어야하기 때문에 Hash Right Join이 선택되는 것을 확인할 수 있다.
- 그렇다면
Outer Join의 경우에 Hash Join과 Hash Outer Join 중 Hash Outer Join이 무조건 선택될까? - 이번에도 똑똑한 옵티마이저는 당연히 그렇지 않다.

- 위와같이 where 절에 member 테이블에 대한 조회조건을 걸었다. 이렇게 되면 Outer Join을 유지하는 것이 무의미하다.
- 이런 경우에도 옵티마이저는 Hash Outer Join 대신 Hash Join을 선택한다.
조인 선택 기준 (마무리)
- 위에서 학습한 내용을 바탕으로 옵티마이저가 조인을 선택하는 기준을 도식화 하면 아래와 같다.물론, 옵티마이저의 판단 기준은 훨씬 복잡하기 때문에, 위의 조건대로 조인이 선택된다는 보장은 없다.

References
'Database' 카테고리의 다른 글
| PostgreSQL 실행계획 분석하기 5편 (Aggregates) (0) | 2023.11.25 |
|---|---|
| PostgreSQL 실행계획 분석하기 4편 (Sort, Limit) (1) | 2023.11.22 |
| PostgreSQL 실행계획 분석하기 2편 (Table Scan) (2) | 2023.11.18 |
| PostgreSQL 실행계획 분석하기 1편 (실행계획 읽는 방법) (0) | 2023.11.16 |
| PostgreSQL 옵티마이저 (0) | 2023.11.14 |