개요
- JPA를 통해서 10만 건 이상의 데이터를 저장하는 경우 성능 이슈가 발생한다는 문의가 들어왔다.
- 평소에 나는 JPA로 대량의 데이터를 저장할 때에 성능적으로 문제가 있다는 사실은 알고 있었으나 그 원인을 정확히 설명하진 못했다.
- 이번 글에서는 위 문제를 해결하기 위한 과정을 정리해 보려고 한다.
- 결론부터 말하자면, 나는 JdbcTemplate의 batchUpdate() 메소드를 사용해서 문제를 해결했다.
먼저 Spring Data JPA의 saveAll()메소드의 실행 과정과 JdbcTemplate의 batchUpdate() 메소드의 실행 과정부터 알아보자.
Spring Data JPA의 saveAll()메소드가 실행되는 과정
- 먼저 Spring Data JPA의 saveAll() 메소드가 실행되는 과정을 살펴보자.

- 삽입할 엔티티목록을 인자로 담아서 saveAll() 메소드를 호출하게 되면, JPA의 persist() 메소드가 엔티티의 개수만큼 실행되어 지연저장소(ActionQueue)에 저장된다.
- 그 다음 지연저장소(ActionQueue)에 담겨있는 엔티티목록을 넘겨서 Insert 쿼리 생성 후, JDBC Driver에서 PreparedStatement로 실행한다.
- application.yaml에서 설정한 batch_size만큼 나눠서 실행한다.
- 만약 엔티티목록이 1만 건이고 batch_size가 1000이면 총 10번에 나눠서 실행한다.
- 실제 구현체를 포함하면 아래와 같이 표현할 수 있다.사실 위 과정 사이에는 훨씬 더 복잡한 과정들이 있다.

- JPA로 대량의 데이터를 저장하는 것은 꽤나 무거운 작업이라는 것을 알 수 있다.
- 물론 batch_size만큼씩 묶어서 쿼리를 실행하기 때문에 bulk insert의 효과는 얻을 수 있지만, 여전히 무거운 작업인 것은 부정할 수 없다.
- 또한 지연저장소(ActionQueue)에 저장할 엔티티목록만큼 엔티티가 저장되어 있기 때문에 메모리도 상당히 많이 차지한다.
- batch_size가 1000이라고 해도 저장하고자 하는 모든 엔티티목록을 ActionQueue에 담기 때문이다.
JdbcTemplate의 batchInsert()메소드가 실행되는 과정
- JdbcTemplate의 batchInsert()메소드가 실행되는 과정은 아래와 같다.

- JPA에 비해서 훨씬 간단한 것을 확인할 수 있다.
- 그렇기 때문에 수행시간이 훨씬 빠르고, 메모리 사용량도 훨씬 적다.
- 하지만, 단점은 Insert 쿼리를 직접 생성해서 넘겨줘야 한다는 것이다.
요구사항 정리
개발자분들이 원하는 기능은 아래와 같다.
1. JPA의 saveAll() 메소드를 대체할 수 있어야 한다.
2. JPA의 saveAll() 처럼 개발자 입장에서 편하게 사용할 수 있어야한다.- 1번 요구사항은 JdbcTemplate을 사용하면 된다.
- 하지만 2번 요구사항을 만족 시키기 위해서는 자동으로 쿼리를 만들어 주는 기능이 필요하다.
엔티티 클래스 구조
- 엔티티 구조는 아래와 같다고 가정하자.
@Entity
@Table(name = "temp_employee")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class TempEmployee extends BaseEntity {
@Id
@GenericGenerator(
name = "temp_employee_seq_generator",
strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",
parameters = {
@org.hibernate.annotations.Parameter(name = "sequence_name", value = "temp_employee_seq"),
@org.hibernate.annotations.Parameter(name = "optimizer", value = "pooled"),
@org.hibernate.annotations.Parameter(name = "initial_value", value = "1"),
@org.hibernate.annotations.Parameter(name = "increment_size", value = "1")
}
)
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "temp_employee_seq_generator"
)
@Column(name = "employee_id", nullable = false)
private Long employeeId;
@Column(name = "employee_name")
private String employeeName;
@Column(name = "begin_date", length = 8)
private String beginDate;
@Column(name = "end_date", length = 8)
private String endDate;
@Builder
public TempEmployee(Long employeeId, String employeeName, String beginDate, String endDate) {
this.employeeId = employeeId;
this.employeeName = employeeName;
this.beginDate = beginDate;
this.endDate = endDate;
}
}- 위 엔티티를 보면, 시퀀스를 가지고 있다.
- 나는 위 엔티티 클래스 정보를 조회해서 Insert 쿼리를 만드는 기능을 구현할 것이다.
- 그리고 BaseEntity를 상속받고 있다.
@MappedSuperclass
@Getter
@EntityListeners(AuditingEntityListener.class)
public class BaseEntity {
@CreatedDate
@Column(name = "created_date")
protected LocalDateTime createdDate;
@LastModifiedDate
@Column(name = "last_modified_date")
protected LocalDateTime lastModifiedDate;
}- BaseEntity에서는 JPA의 Audit 기능을 사용해서 생성일자와 수정일자를 저장하고 있다.
2번 요구사항을 해결하기 위해서는 batchUpdate의 단점인 쿼리를 직접 생성해야 하는 부분을 해결해야 한다. 이제 본격적으로 기능을 구현해보자.
쿼리 생성 로직
- 소스 코드는 아래와 같다.

- 위 코드를 보면 엔티티 클래스 타입을 인자로 받아서 해당 엔티티의 정보를 추출한 후에 Insert 쿼리를 만들고 있다.
- 만약, 시퀀스가 없다면 SequenceNotFoundException라는 예외를 던진다.
Batch Insert 실행 로직
- 소스 코드는 아래와 같다.

- 위에서 설펴본 createInsertQueryFromEntity() 메소드를 통해서 쿼리를 생성한다.
- 그리고 BeanPropertySqlParameterSource를 상속받아서 CustomBeanPropertySqlParameterSource를 만들었다. (해당 클래스는 아래서 설명한다.)
- 전달받은 엔티티목록으로 파라미터를 생성한다.
- JdbcTemplate을 Wrapping 한 클래스인 NamedParameterJdbcTemplate를 기반으로 batchUpdate 메소드를 호출하여 데이터를 삽입한다.
- 전체 소스 코드는 아래와 같다.
EntityBatchInsertRepository 전체 코드
import org.springframework.stereotype.Component;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import javax.persistence.Table;
import javax.persistence.Id;
import javax.persistence.Column;
import org.hibernate.annotations.GenericGenerator;
import org.hibernate.annotations.Parameter;
import org.springframework.util.StringUtils;
import java.lang.reflect.Field;
import java.util.List;
import java.util.StringJoiner;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* Batch Insert Repository
* <p>
* 이 리포지토리는 JdbcTemplate의 batchUpdate 기능을 사용하여 대량 데이터 삽입을 수행합니다.
* JPA의 saveAll 메소드와 비교하여 더 빠른 성능과 적은 메모리 사용량을 제공합니다.
*
* @param <T> 엔티티 클래스 타입
*/
@Component
@Slf4j
@RequiredArgsConstructor
public class EntityBatchInsertRepository<T> {
private final NamedParameterJdbcTemplate namedParameterJdbcTemplate;
private final Map<Class<?>, String> insertQueryCache = new ConcurrentHashMap<>();
/**
* 배치 삽입 작업 수행
* <p>
* 엔티티 리스트에 대한 배치 삽입 SQL 쿼리를 생성하고 실행합니다.
*
* @param entityList 삽입할 엔티티 리스트
* @param entityClass 엔티티 클래스
* @return 각 배치 작업에 대한 영향을 받은 행 수를 나타내는 정수 배열
*/
public int[] batchInsert(final List<T> entityList, final Class<T> entityClass) {
// 쿼리 생성
String sql = createInsertQueryFromEntity(entityClass);
// 파라미터 생성
SqlParameterSource[] sqlParameterSources = entityList.stream()
.map(CustomBeanPropertySqlParameterSource::new)
.toArray(SqlParameterSource[]::new);
// Batch Insert 실행
return namedParameterJdbcTemplate.batchUpdate(sql, sqlParameterSources);
}
/**
* 엔티티 클래스로부터 insert SQL 쿼리 생성
* <p>
* 엔티티 클래스의 어노테이션을 사용하여 insert SQL 쿼리를 생성합니다.
* 생성된 쿼리는 미래에 재사용하기 위해 캐시됩니다.
*
* @param entityClass 엔티티 클래스
* @return 생성된 SQL insert 쿼리 문자열
*/
private String createInsertQueryFromEntity(Class<?> entityClass) {
return insertQueryCache.computeIfAbsent(entityClass, cls -> {
Table table = cls.getAnnotation(Table.class);
String tableName = (table != null && !table.name().isEmpty()) ? table.name() : cls.getSimpleName().toLowerCase();
StringJoiner columnNames = new StringJoiner(", ");
StringJoiner placeholders = new StringJoiner(", ");
String sequenceName = null;
for (Field field : cls.getDeclaredFields()) {
// 시퀀스 조회
if (field.isAnnotationPresent(Id.class)) {
sequenceName = processIdField(field, tableName);
}
Column column = field.getAnnotation(Column.class);
if (column != null) {
String columnName = column.name().isEmpty() ? field.getName() : column.name();
columnNames.add(columnName);
placeholders.add(field.isAnnotationPresent(Id.class) ? "nextval('" + sequenceName + "')" : ":" + field.getName());
}
}
// BaseEntity 필드 처리
Class<?> superclass = cls.getSuperclass();
for (Field field : superclass.getDeclaredFields()) {
Column column = field.getAnnotation(Column.class);
if (column != null) {
String columnName = column.name().isEmpty() ? field.getName() : column.name();
columnNames.add(columnName);
placeholders.add(":" + field.getName());
}
}
return String.format("INSERT INTO %s (%s) VALUES (%s)", tableName, columnNames, placeholders);
});
}
private String processIdField(Field field, String tableName) {
GenericGenerator genericGenerator = field.getAnnotation(GenericGenerator.class);
if (genericGenerator != null) {
for (Parameter parameter : genericGenerator.parameters()) {
if ("sequence_name".equals(parameter.name())) {
String sequenceName = parameter.value();
if (!StringUtils.hasText(sequenceName)) {
throw new RuntimeException(String.format("테이블: '%s'에 대한 시퀀스가 존재하지 않습니다.", tableName));
}
return sequenceName;
}
}
}
return null;
}
}CustomBeanPropertySqlParameterSource 구현
- BeanPropertySqlParameterSource는 Java Bean의 프로퍼티 이름을 SQL 쿼리 내의 파라미터 이름과 자동으로 매핑하는 클래스다.
- 하지만 BeanPropertySqlParameterSource를 그대로 사용하기에는 아래와 같은 문제들이 있었다.
1. BeanPropertySqlParameterSource는 LocalDateTime 타입을 차리하지 못한다.
2. JPA의 Auditing 기능이 적용된 createdDate와 lastModifiedDate에 대한 처리가 필요하다.1번 문제 해결
- BeanPropertySqlParameterSource의 getSqlType()에서 StatementCreatorUtils.javaTypeToSqlParameterType()를 호출한다.
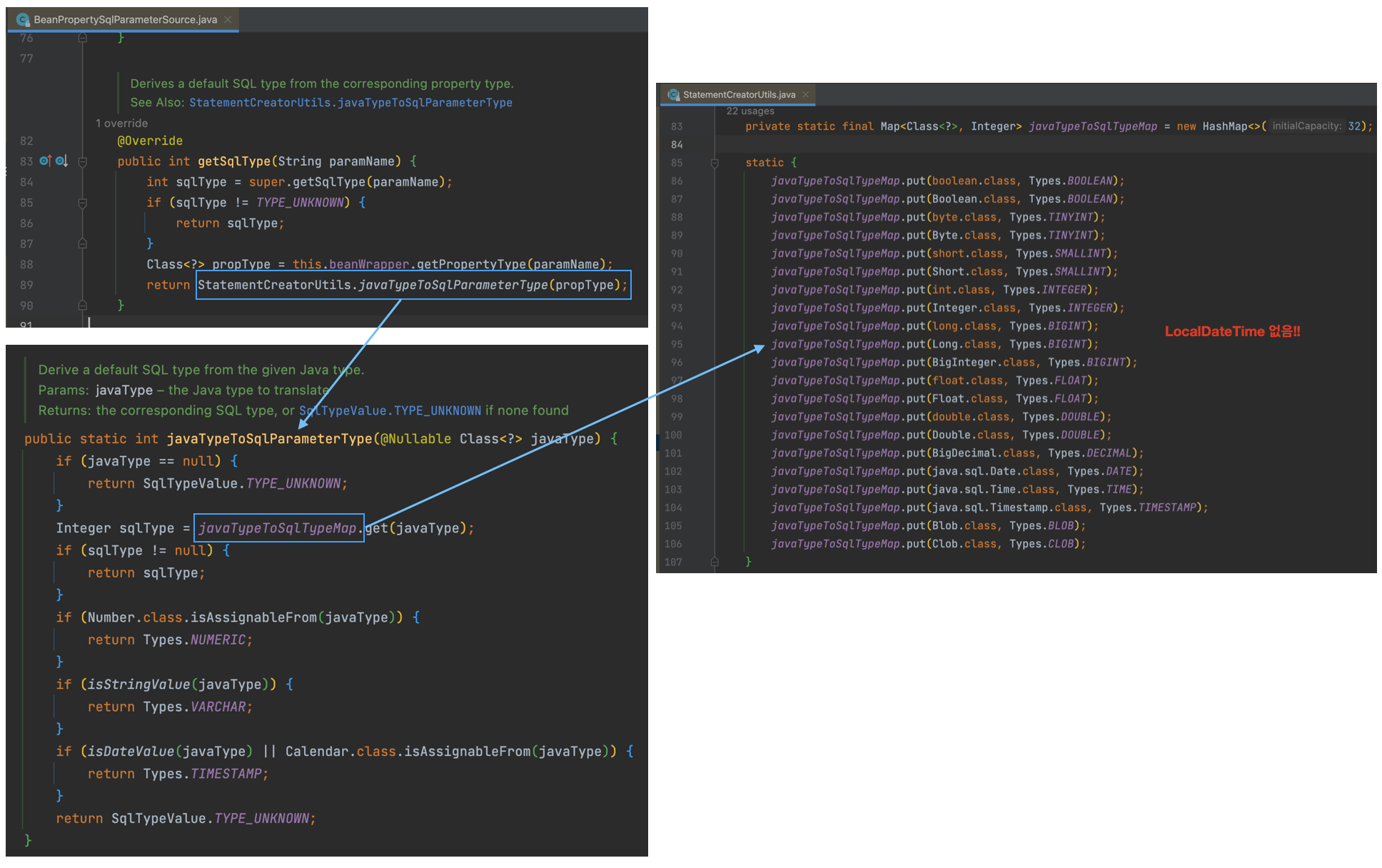
- javaTypeToSqlParameterType()를 보면
javaTypeToSqlTypeMap를 통해서 sqlType를 가져오는데 LocalDateTime이 javaTypeToSqlTypeMap이 빠져있는 것을 확인할 수 있다. - javaTypeToSqlTypeMap에 LocalDateTime이 추가된 것은 spring-jdbc-5.3.22이다. 내용은 아래와 같다.

- spring-jdbc github 링크
- 나는 spring-jdbc-5.2.4 여서 BeanPropertySqlParameterSource를 상속받아서 CustomBeanPropertySqlParameterSource를 구현했다. 코드는 아래와 같다.

- 위와 같이 javaTypeToSqlTypeMap에 LocalDateTime을 추가했다.
- 그리고 getSqlType() 메소드를 오버라이드해서 수정된 javaTypeToSqlTypeMap를 사용하도록 수정했다.
- 위에서 언급했듯이 spring-jdbc-5.3.22 버전 이상을 사용하고 있는 환경이라면 이 작업은 불필요하다.
2번 문제 해결
- 2번 문제는 JPA의 Auditing 기능을 구현해줘야 하는 것이다.
- 이 문제의 해결법은 간단하다. insert 시점에 현재 시간을 넣어주면 된다. 코드는 아래와 같다.

- 위와 같이 getValue()메소드를 오버라이드 해서 createDate, lastModifiedDate에 현재 시간을 넣어줬다.
CustomBeanPropertySqlParameterSource 전체 코드
import org.springframework.beans.BeanWrapper;
import org.springframework.beans.PropertyAccessorFactory;
import org.springframework.jdbc.core.SqlTypeValue;
import org.springframework.jdbc.core.namedparam.BeanPropertySqlParameterSource;
import org.springframework.lang.NonNull;
import org.springframework.lang.Nullable;
import java.math.BigDecimal;
import java.math.BigInteger;
import java.sql.Blob;
import java.sql.Clob;
import java.sql.Types;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.LocalTime;
import java.util.*;
/**
* Custom BeanPropertySqlParameterSource
* <P>
* LocalDateTime 타입 처리와 JPA Auditing기능을 대체하기 위해서 {@link BeanPropertySqlParameterSource} 를 재구현 하였습니다.
*/
public class CustomBeanPropertySqlParameterSource extends BeanPropertySqlParameterSource {
private final BeanWrapper beanWrapper;
private final Set<String> baseEntityFieldSet = new HashSet<>(Arrays.asList("createdDate", "lastModifiedDate"));
private static final Map<Class<?>, Integer> javaTypeToSqlTypeMap = new HashMap<>(32);
static {
javaTypeToSqlTypeMap.put(boolean.class, Types.BOOLEAN);
javaTypeToSqlTypeMap.put(Boolean.class, Types.BOOLEAN);
javaTypeToSqlTypeMap.put(byte.class, Types.TINYINT);
javaTypeToSqlTypeMap.put(Byte.class, Types.TINYINT);
javaTypeToSqlTypeMap.put(short.class, Types.SMALLINT);
javaTypeToSqlTypeMap.put(Short.class, Types.SMALLINT);
javaTypeToSqlTypeMap.put(int.class, Types.INTEGER);
javaTypeToSqlTypeMap.put(Integer.class, Types.INTEGER);
javaTypeToSqlTypeMap.put(long.class, Types.BIGINT);
javaTypeToSqlTypeMap.put(Long.class, Types.BIGINT);
javaTypeToSqlTypeMap.put(BigInteger.class, Types.BIGINT);
javaTypeToSqlTypeMap.put(float.class, Types.FLOAT);
javaTypeToSqlTypeMap.put(Float.class, Types.FLOAT);
javaTypeToSqlTypeMap.put(double.class, Types.DOUBLE);
javaTypeToSqlTypeMap.put(Double.class, Types.DOUBLE);
javaTypeToSqlTypeMap.put(BigDecimal.class, Types.DECIMAL);
javaTypeToSqlTypeMap.put(java.sql.Date.class, Types.DATE);
javaTypeToSqlTypeMap.put(java.sql.Time.class, Types.TIME);
javaTypeToSqlTypeMap.put(java.sql.Timestamp.class, Types.TIMESTAMP);
javaTypeToSqlTypeMap.put(Blob.class, Types.BLOB);
javaTypeToSqlTypeMap.put(Clob.class, Types.CLOB);
javaTypeToSqlTypeMap.put(LocalDate.class, Types.DATE); //추가
javaTypeToSqlTypeMap.put(LocalTime.class, Types.TIME); //추가
javaTypeToSqlTypeMap.put(LocalDateTime.class, Types.TIMESTAMP); //추가
}
public CustomBeanPropertySqlParameterSource(Object object) {
super(object);
this.beanWrapper = PropertyAccessorFactory.forBeanPropertyAccess(object);
}
/**
* BaseEntity 필드와 암호화 필드 처리
*
* @param paramName 파라미터 이름
* @return 파라미터 값
* @throws IllegalArgumentException 유효하지 않은 파라미터 이름일 경우 발생
*/
@Override
public Object getValue(@NonNull String paramName) throws IllegalArgumentException {
// BaseEntity 컬럼 처리
if (baseEntityFieldSet.contains(paramName)) {
return LocalDateTime.now(); // 현재 시간으로 설정
}
return super.getValue(paramName);
}
@Override
public int getSqlType(@NonNull String paramName) {
int sqlType = super.getSqlType(paramName);
if (sqlType != TYPE_UNKNOWN) {
return sqlType;
}
Class<?> propertyType = beanWrapper.getPropertyType(paramName);
return javaTypeToSqlParameterType(propertyType);
}
private int javaTypeToSqlParameterType(@Nullable Class<?> javaType) {
if (javaType == null) {
return SqlTypeValue.TYPE_UNKNOWN;
}
Integer sqlType = javaTypeToSqlTypeMap.get(javaType);
if (sqlType != null) {
return sqlType;
}
return SqlTypeValue.TYPE_UNKNOWN;
}
}성능 비교
성능비교에 사용되는 추가적인 클래스를 구현했다. 코드의 구현은 이번 주제에서 벗어나기 때문에 넘어가도 좋다. (성능 비교에 주목하자.)
추가 클래스 구현
- 성능 비교를 위해서 2개의 유틸 클래스를 구현한다.
- ExecutionTimeUtil: 걸린 시간 측정을 위한 Util 클래스
- MemoryUsageUtil: 메모리 사용량을 측정하기 위한 클래스
ExecutionTimeUtil 전체 코드
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.TimeUnit;
import java.util.function.Supplier;
@Slf4j
public class ExecutionTimeUtil {
private ExecutionTimeUtil() {
}
public static <T> T measureTime(Supplier<T> task) {
long startTime = System.nanoTime();
T result = task.get(); // 작업 실행 및 결과 반환
long endTime = System.nanoTime();
long duration = endTime - startTime;
log.info("총 걸린시간: {} ms", TimeUnit.NANOSECONDS.toMillis(duration));
return result; // 측정된 작업의 결과 반환
}
}MemoryUsageUtil 전체 코드
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.ScheduledFuture;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
@Slf4j
public class MemoryUsageUtil {
private static final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(10);
private static final long MEGABYTE = 1024L * 1024L;
private MemoryUsageUtil() {
}
public static void logMemoryUsagePerSecond(Runnable task, int period) {
try {
Thread.sleep(100L); // 약간의 지연
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("Interrupted during sleep", e);
}
long initUsedMemory = getCurrentUsedMemory();
AtomicLong maxUsedMemory = new AtomicLong(initUsedMemory);
// 최대 메모리 사용량 측정 (1 나노초 마다 반복)
final ScheduledFuture<?> maxUsedMemoryHandle = scheduler.scheduleAtFixedRate(() -> {
long currentUsedMemory = getCurrentUsedMemory();
maxUsedMemory.updateAndGet(max -> Math.max(max, currentUsedMemory));
}, 0, 1, TimeUnit.NANOSECONDS);
// period 마다 반복해서 로깅
final ScheduledFuture<?> logHandle = scheduler.scheduleAtFixedRate(() -> {
logMemoryUsage("주기적 로깅");
}, 0, period, TimeUnit.SECONDS);
task.run();
maxUsedMemoryHandle.cancel(false);
logHandle.cancel(false);
logMemorySummary(bytesToMegabytes(initUsedMemory), bytesToMegabytes(maxUsedMemory.get()));
}
private static void logMemorySummary(long initialMemory, long maxMemory) {
String message = String.format("Task 실행 시점의 메모리 사용량: %s MB, Task 실행 중 최대 메모리 사용량: %s MB, Task 처리 과정에서 사용한 최대 메모리 사용량: %s MB",
initialMemory,
maxMemory,
maxMemory - initialMemory);
log.info(message);
}
private static long getCurrentUsedMemory() {
Runtime runtime = Runtime.getRuntime();
return runtime.totalMemory() - runtime.freeMemory();
}
public static void logMemoryUsage(String prefix) {
Runtime runtime = Runtime.getRuntime();
long maxMemory = runtime.maxMemory();
long allocatedMemory = runtime.totalMemory();
long freeMemory = runtime.freeMemory();
long usedMemory = allocatedMemory - freeMemory;
String message = String.format("%sCurrent memory usage: Used Memory = %s MB, Free Memory = %s MB, Total Allocated Memory = %s MB, Max Memory = %s MB",
prefix.isEmpty() ? "" : prefix + " - ",
bytesToMegabytes(usedMemory),
bytesToMegabytes(freeMemory),
bytesToMegabytes(allocatedMemory),
bytesToMegabytes(maxMemory));
log.info(message);
}
private static long bytesToMegabytes(long bytes) {
return bytes / MEGABYTE;
}
}데이터 세팅
아래와 같이 100만 건의 데이터를 세팅했다.
DO $$
DECLARE
i INT := 0;
BEGIN
WHILE i < 100000 LOOP
INSERT INTO employee (begin_date, employee_name, end_date, employee_code, last_modified_date, created_date)
VALUES (
TO_CHAR(NOW() - INTERVAL '1 year' * RANDOM(), 'YYYYMMDD'),
'Employee ' || i,
TO_CHAR(NOW() - INTERVAL '6 months' * RANDOM(), 'YYYYMMDD'),
'E' || LPAD(i::TEXT, 6, '0'),
NOW(),
NOW()
);
i := i + 1;
END LOOP;
END $$;비교할 로직

비교할 로직은 간단하다. employee 테이블의 데이터를 전부 가져와서 temp_employee 테이블에 삽입하는 것이다.
실행 시간 비교
- JPA saveAll()의 경우 45306ms가 걸렸다.
- 반면, JdbcTemplate의 경우 1201ms가 걸렸다.
- 약 46507배로 빨라졌다.
메모리 사용량 비교

- Task 처리 과정에서 사용한 최대 메모리 사용량은 '메소드 수행중 최대 메모리 사용량 - 메소드 진입 시점의 메모리량'이다.
- Task 처리 과정에서 사용한 평균 메모리 사용량은 메소드 실행 과정에서 1초마다 메모리 상태를 저장한 뒤, 평균을 구한 값이다. (데이터가 적을 시 오차가 크다)
- 메모리 사용량을 보면 거의 비슷한 것을 확인할 수 있다. (이 부분은 하단에서 좀 더 자세히 설명한다.)
테스트 코드
@SpringBootTest
class EmployeeServiceTest {
@Autowired
private EmployeeRepository employeeRepository;
@Autowired
private TempEmployeeRepository tempEmployeeRepository;
@Autowired
private EntityBatchInsertRepository<TempEmployee> employeeEntityBatchInsertRepository;
private List<TempEmployee> prepareTempEmployeeData() {
return employeeRepository.findAll().stream()
.map(employee -> TempEmployee.builder()
.employeeName(employee.getEmployeeName())
.beginDate(employee.getBeginDate())
.endDate(employee.getEndDate())
.build())
.collect(Collectors.toList());
}
@BeforeEach
void setup() {
tempEmployeeRepository.deleteAll();
}
@Test
@DisplayName("JPA saveAll() 수행시간 측정")
public void jpaSaveAllExecutionTimeTest() {
List<TempEmployee> newEntityList = prepareTempEmployeeData();
ExecutionTimeUtil.measureTime(() -> tempEmployeeRepository.saveAll(newEntityList));
}
@Test
@DisplayName("JdbcTemplate batchUpdate() 수행시간 측정")
public void jdbcTemplateBatchUpdateExecutionTimeTest() {
List<TempEmployee> newEntityList = prepareTempEmployeeData();
ExecutionTimeUtil.measureTime(() -> employeeEntityBatchInsertRepository.batchInsert(newEntityList, TempEmployee.class));
}
@Test
@DisplayName("JPA Bulk Insert 메모리 측정")
public void jpaSaveAllMemoryUsageTest() {
List<TempEmployee> newEntityList = prepareTempEmployeeData();
MemoryUsageUtil.logMemoryUsagePerSecond(() -> tempEmployeeRepository.saveAll(newEntityList), 1);
}
@Test
@DisplayName("JdbcTemplate Bulk Insert 메모리 측정")
public void jdbcTemplateMemoryUsageTest() {
List<TempEmployee> newEntityList = prepareTempEmployeeData();
MemoryUsageUtil.logMemoryUsagePerSecond(() -> employeeEntityBatchInsertRepository.batchInsert(newEntityList, TempEmployee.class), 1);
}
}데어터 건수 별 성능 평가
아래 성능평가는 추정치에 불가하다. 특히 메모리 평균 사용량은 1초마다 메모리상태를 저장한 뒤 평균값을 구하기 때문에 정확하지 않을 확률이 높다. 다만 이번 성능평가는 정확한 수치를 보기보다는 추세를 보는 것에 집중하자.
테스트 환경
CPU: Apple M1 (10 Core)
RAM: 32GB
JVM: -Xms6144m -Xmx6144m
JPA의 saveAll() 건수 별 성능 측정
| 건수 | 실행시간 | 메모리 사용량 | 메모리 평균 사용량 |
|---|---|---|---|
| 1만 건 | 4109ms | 34MB | 125MB |
| 10만 건 | 45306ms | 237MB | 337MB |
| 100만 건 | 418540ms | 1779MB | 1607MB |
| 500만 건 | 오랜 시간 | 5000MB이상 | 4000MB이상 |
- 메모리 사용량은 위에서 언급했던 Task 처리 과정에서 사용한 최대 메모리 사용량을 의미한다.
- 주로 봐야할 수치는 실행시간과 메모리 사용량이다.
- 위 결과를 보면, 수행시간은 건 수에 비례하게 증가하는 것 같다.
- 나는 JPA의 경우 batch_size 만큼씩 끊어서 쿼리를 실행하기 때문에 이미 전송한 데이터는 메모리에서 지우기를 기대했다.
- 하지만 초반에도 언급했듯이 쿼리를 실행하기 전에 ActionQueue(지연저장소)에 데이터를 저장하는 작업부터 시작한다.
- 그렇기 때문에 메모리 사용량 또한 계속해서 증가하게 된다.
JdbcTemplate의 batchUpdate() 건수 별 성능 측정
| 건수 | 실행시간 | 메모리 사용량 | 메모리 평균 사용량 |
|---|---|---|---|
| 1만 건 | 170ms | 28MB | 214MB |
| 10만 건 | 1201ms | 192MB | 327MB |
| 100만 건 | 12061ms | 1276MB | 1766MB |
| 500만 건 | 60171ms | 3456MB | 6168MB |
- 위 결과를 보면, 수행시간과 메모리 사용량은 건 수에 비례하게 증가하는 것 같다.
정리
- 성능 평가의 결과를 보면 10만 건부터는 JdbcTemplate을 사용하는 방식이 수행시간이 훨씬 효율적인 것을 확인할 수 있다.
- JPA의 saveAll() 메소드는 사실상 10만 건이 넘어가면 사용하지 않는 것이 바람직한 것 같다.
- 수행 시간과 메모리 사용량 모두 비효율적이기 때문이다.
- 하지만 데이터가 너무 대량일 경우, JdbcTemplate 또한 메모리 사용량에 주의해야 한다.
- JdbcTemplate의 batchUpate() 메소드는 건수가 비례하게 계속 증가하기 때문에 일정 크기가 넘어간다면, chunk 단위로 나눠서 실행해야 한다.
'Spring Jpa' 카테고리의 다른 글
| JPA에서 여러 종류의 영속성 관리하기 (1) | 2023.08.28 |
|---|---|
| JPA 관련 애노테이션 정리 (0) | 2022.03.24 |
| JPA DB 수동설정 (0) | 2022.03.24 |
| 프록시와 연관관계 관리 (0) | 2022.02.27 |
| JPA Id 생성전략 설정하기 (0) | 2022.02.27 |