개요
- Spring Batch는 대용량 데이터를 처리하는 데 최적화되어 있는 기능들을 제공하는 프레임워크다.
- 나는 실제로 Spring Batch를 사용해서 대용량 데이터 처리를 효율적으로 처리했다.
- 이번 글에서는 Spring Batch를 사용해서 대용량 데이터를 처리하는 방법에 대해서 정리해 보려고 한다.
필수 사전 지식
- Spring Batch Architecture
왜 Spring Batch가 대용량 데이터 처리에 유리한가?
Spring Batch가 대용량 데이터 처리에 유리한 이유는 크게 3가지다.
- Chunk-oriented Processing
- Spring Batch는 대량의 데이터를 Chunk 단위로 나누어 처리한다.
- 그렇기 때문에 메모리를 효율적으로 사용할 수 있다.
- 작업 실패 시, 실패한 Chunk에 대해서만 트랜잭션만 롤백되기 때문에 세밀하게 트랜잭션을 관리할 수 있다.
- Restartability
- Spirng Batch는 오류가 발생했을 때 처음부터 다시 시작하는 대신, 마지막으로 성공적으로 처리된 지점부터 재시작할 수 있다.
- 그렇기 때문에 대용량 데이터 처리에 있어 시간과 리소스를 절약할 수 있다.
- Scaling and Parallel Processing
- Spring Batch는
Multi-threaded Step, Parallel Steps, Partitioning Step를 통해서 Scaling and Parallel Processing를 지원한다. (이 부분은 아래에 좀 더 자세히 설명한다.)
- Spring Batch는
나는 Multi-threaded Step과 Partitioning Step 사용했다. 이제 Multi-threaded Step, Partitioning Step에 대해서 좀 더 자세히 알아보자.
Multi-threaded Step
Multi-threaded Step의 구조는 아래와 같다.

- Multi-threaded Step는 Chunk 단위로 병렬처리를 진행한다.
- 만약 1개의 Step이 4개의 Chunk로 쪼개져서 실행된다면, 위와 같이 4개의 워커 스레드가 병렬로 처리하게 된다.
- 정리해 보면 하나의 스탭을 Chunk 단위로 병렬처리하는 것이다. (스탭을 여러 개로 쪼개는 것은 아니다.)
- 여기서 주의할 점은 처리순서는 보장되지 않는다는 점이다. 따라서 여러 개의 여러 개의 Chunk가 순서가 보장되어야 한다면 사용할 수 없다.
- 주요 코드는 아래와 같다.보다시피 Multi-threaded를 적용하는 것은 매우 간단하다.

- Chunk를 병렬로 처리할 TaskExecutor를 구현해서 Step을 정의할 때 넣어주기만 하면 된다.
- 여기서 주의할 점은 스레드 풀의 크기와 throttleLimit의 크기를 맞춰줘야한다.
- Step을 정의할때 throttleLimit값은 이후 TaskExecutorRepeatTemplate의 청크를 병렬로 반복 실행하는 역할을 하는데 기본값이 4이기 때문에 이 값을 스레드풀의 크기와 맞춰줘야 제대로 병렬처리가 가능하다.
Partitioning Step
Partitioning Step의 구조는 아래와 같다.

- Partitioning Step은 하나의 Step을 여러 개로 쪼개는 것이다.
- 정확히는 Step이 복사되는 건 아니고, StepExecution이 여러 번 실행되는 것이다.
- 주요 코드는 아래와 같다.
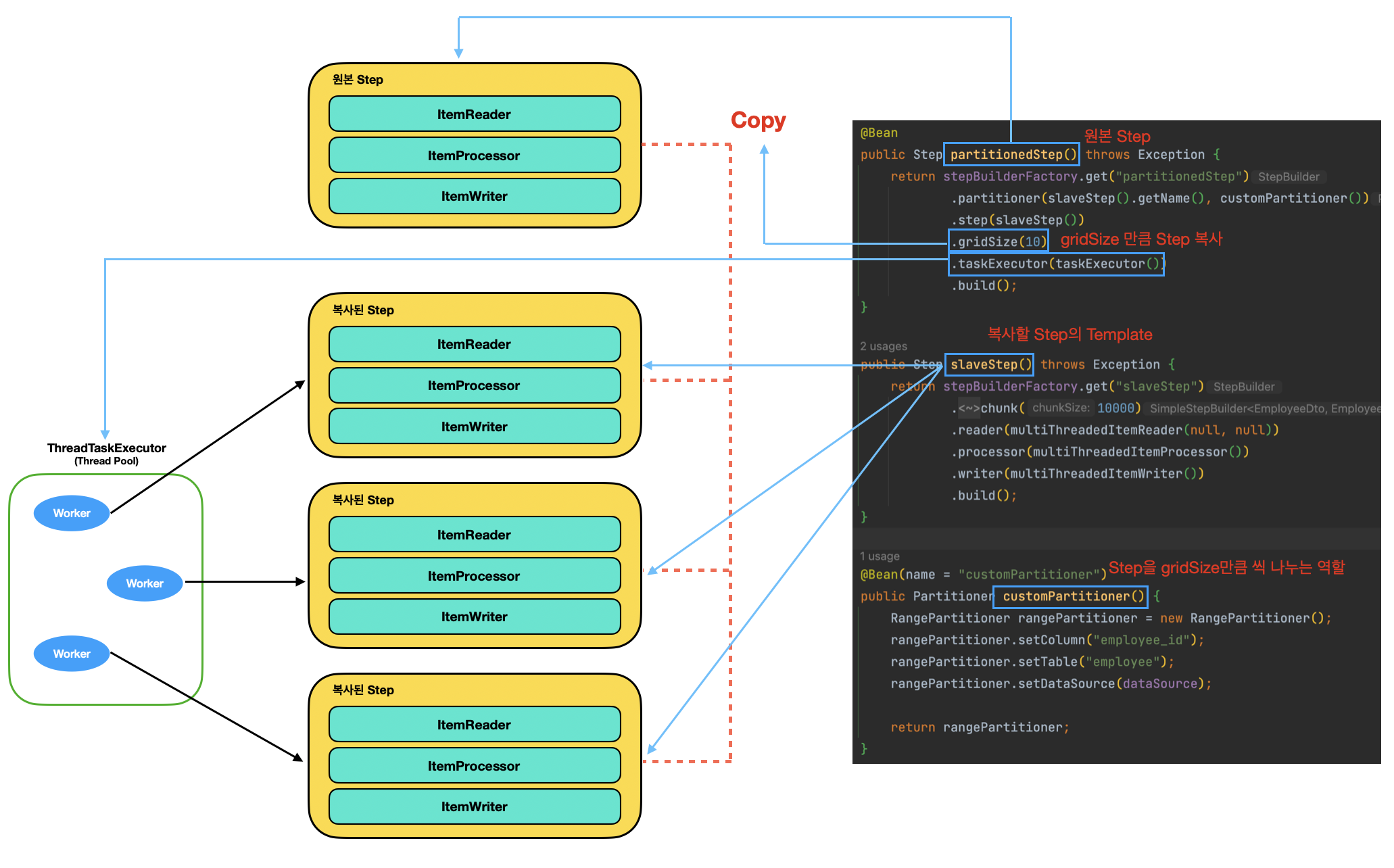
- Partitioning Step은 Multi-threaded Step에 비해서 다소 복잡하다.
- 먼저 원본 Step에서 gridSize를 설정해서 얼마만큼 Step을 복사할 건지 설정한다.
- 그다음 복사된 Step을 병렬로 처리하기 위한 Thread Pool(TaskExecutor)를 정의한다.
- 그리고 복사할 Step의 Template을 정의한다.
- 마지막으로 Step을 gridSize만큼 씩 나누는 역할을 하는 partitioner를 구현해 주면 된다.
- 여기서 주의할 점은 ThreadTaskExecutor를 구성할 때, corePoolSize를 gridSize와 동일하게 해주는 것이 좋다.
- 예를 들어, corePoolSize가 5인데 gridSize가 10이라면 5개의 Step은 바로 실행되지만 나머지 5개는 이전 Step이 끝날 때까지 대기하기 때문이다.
- maxPoolSize 가 10이라고 할지라도 corePoolSize이상의 task는 대기큐에 쌓고, 대기큐가 가득 찼을 때에 스레드풀에 스레드를 추가로 생성하기 때문이다.
Multi-threaded Step은 하나의 Step을 병렬로 처리 방식이고, Partitioning Step는 Step 자체를 여러 개로 쪼개서 병렬처리하는 것이다. 그렇다면 두 방식을 동시에 사용하면 어떨까?
Multi-threaded Step + Partitioning Step
Multi-threaded Step 와 Partitioning Step 동시에 사용하는 구조는 아래와 같다.

- Partitioning Step을 통해서 하나의 Step을 여러 개로 쪼개서 병렬처리 한다.
- 쪼개진 Step을 다시 Chunk 단위로 병렬처리 한다.
- 주요 코드는 아래와 같다.

- 위와 같이 Partitioning Step에서 복사할 Step의 Template을 정의할 때에 TaskExecutor를 구현해서 Step을 정의할 때 넣어주면 된다.
- 위 그림에서 볼 수 있듯이 두 가지 방식을 동시에 사용하게 되면 대량의 데이터를 여러 개로 쪼개서 쿼리가 나가기 때문에 자칫 Connection 사용량이 많다는 것도 주의해야 한다.
- 또한, Multi-threaded를 처리하는 스레드풀의 크기도 잘 설정해야 한다.
- Multi-threaded만 처리할 때보다 스레드풀의 크기를 좀 더 크게 설정하는 것이 좋다.
- 물론 이것도 서버의 환경에 따라 다르다. 시스템의 CPU Core 수 적다면 오히려 성능이 더 나쁠 수 있다.
위에서 정리한 내용만 보면 Multi-threaded + Partitioning 구조가 가장 성능이 좋을 것 같다. 하지만 꼭 그렇진 않다. 현재 하드웨어 자원, 특히 CPU와 메모리의 용량 및 처리 능력에 따라서 달라지기 때문이다. 이제 성능 테스트를 진행해 보자.
테스트 시나리오
간단한 예시로 employee 테이블에 있는 데이터를 읽어와서 employee_name에 담긴 데이터를 가공한 뒤, temp_employee로 복사하는 Job을 구성해 보자.
테이블 및 데이터
create table employee
(
employee_id bigint generated by default as identity
constraint employee_pkey
primary key,
begin_date varchar(8),
employee_name varchar(255),
employee_code varchar(255),
end_date varchar(8),
last_modified_date timestamp,
created_date timestamp
);create table temp_employee
(
employee_id bigint generated by default as identity
constraint temp_employee_pkey
primary key,
begin_date varchar(8),
employee_name varchar(255),
employee_code varchar(255),
end_date varchar(8),
last_modified_date timestamp,
created_date timestamp
);DO $$
DECLARE
i INT := 0;
BEGIN
WHILE i < 1000000 LOOP
INSERT INTO employee (begin_date, employee_name, end_date, employee_code, last_modified_date, created_date)
VALUES (
TO_CHAR(NOW() - INTERVAL '1 year' * RANDOM(), 'YYYYMMDD'),
'Employee ' || i,
TO_CHAR(NOW() - INTERVAL '6 months' * RANDOM(), 'YYYYMMDD'),
'E' || LPAD(i::TEXT, 6, '0'),
NOW(),
NOW()
);
i := i + 1;
END LOOP;
END $$;같은 구조로 employee, temp_employee를 구성하고 employee 테이블에는 100만 건의 데이터를 넣어 두었다. 이제 본격적으로 로직을 구성해 보자.
코드 구현
Single Thread Step 코드 예시
먼저, 병렬처리를 하지 않은 가장 일방적인 작업을 구현해 보자.
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.PagingQueryProvider;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.database.builder.JdbcPagingItemReaderBuilder;
import org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class SingleThreadJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private final JdbcTemplate jdbcTemplate;
@Bean(name = "singleThreadJob")
public Job singleThreadJob() throws Exception {
return jobBuilderFactory.get("singleThreadJob")
.start(singleThreadStep())
.listener(new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
jdbcTemplate.execute("TRUNCATE temp_employee;");
}
@Override
public void afterJob(JobExecution jobExecution) {
}
})
.build();
}
@Bean(name = "singleThreadStep")
public Step singleThreadStep() throws Exception {
return stepBuilderFactory.get("singleThreadStep")
.<EmployeeDto, EmployeeDto>chunk(10000)
.reader(singleThreadItemReader())
.processor(singleThreadItemProcessor())
.writer(singleThreadItemWriter())
.build();
}
@Bean(name = "singleThreadItemReader")
@StepScope
public JdbcPagingItemReader<EmployeeDto> singleThreadItemReader() throws Exception {
return new JdbcPagingItemReaderBuilder<EmployeeDto>()
.name("multiThreadItemReader")
.dataSource(dataSource)
.pageSize(10000)
.fetchSize(10000)
.rowMapper(new BeanPropertyRowMapper<>(EmployeeDto.class))
.queryProvider(createQueryProvider())
.build();
}
public PagingQueryProvider createQueryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProviderFactoryBean = new SqlPagingQueryProviderFactoryBean();
queryProviderFactoryBean.setDataSource(dataSource);
queryProviderFactoryBean.setSelectClause("*");
queryProviderFactoryBean.setFromClause("from employee");
Map<String, Order> sortKeys = new HashMap<>(1);
sortKeys.put("employee_id", Order.ASCENDING);
queryProviderFactoryBean.setSortKeys(sortKeys);
return queryProviderFactoryBean.getObject();
}
@Bean(name = "singleThreadItemProcessor")
@StepScope
public ItemProcessor<EmployeeDto, EmployeeDto> singleThreadItemProcessor() {
return item -> {
item.setEmployeeName("Processed " + item.getEmployeeName());
return item;
};
}
@Bean(name = "singleThreadItemWriter")
@StepScope
public JdbcBatchItemWriter<EmployeeDto> singleThreadItemWriter() {
return new JdbcBatchItemWriterBuilder<EmployeeDto>()
.sql("INSERT INTO temp_employee (employee_id, begin_date, employee_name, end_date, employee_code, last_modified_date, created_date) " +
"VALUES (:employeeId, :beginDate, :employeeName, :endDate, :employeeCode, :lastModifiedDate, :createdDate)")
.dataSource(dataSource)
.beanMapped()
.build();
}
}- 위와 같이 Chunk Size를 10000으로 설정해 주었다.
- ItemReader에서는 JdbcPagingItemReader를 사용해서 10000 건 씩 employee 테이블에서 데이터를 읽어오고 있다.
- 그다음 ItemProcessor에서 employee_name 필드에 데이터를 가공한다.
- 마지막으로 ItemWriter에서는 JdbcBatchItemWriter를 사용해서 temp_employee테이블에 넣고 있다.
- 수행시간은 약 15초가 걸렸다.
- JdbcBatchItemWriter는 내부적으로 BatchUpdate 방식으로 동작하기 때문에 100만 건의 데이터를 삽입한다고 하더라도 Chunk 단위로 쿼리 하기 때문에 실제로 쿼리가 나가는 횟수는 100번이다.
- 그렇기 때문에 성능이 좋다.
Multi-threaded Step 코드 예시
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.PagingQueryProvider;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.database.builder.JdbcPagingItemReaderBuilder;
import org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class MultiThreadedJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private final JdbcTemplate jdbcTemplate;
@Bean(name = "multiThreadedJob")
public Job multiThreadedJob() throws Exception {
return jobBuilderFactory.get("multiThreadedJob")
.start(multiThreadedStep())
.listener(new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
jdbcTemplate.execute("TRUNCATE temp_employee;");
}
@Override
public void afterJob(JobExecution jobExecution) {
}
})
.build();
}
@Bean(name = "multiThreadedStep")
public Step multiThreadedStep() throws Exception {
return stepBuilderFactory.get("multiThreadedStep")
.<EmployeeDto, EmployeeDto>chunk(10000)
.reader(multiThreadedItemReader())
.processor(multiThreadedItemProcessor())
.writer(multiThreadedItemWriter())
.taskExecutor(taskExecutor())
.throttleLimit(10)
.build();
}
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); // 초기 스레드 풀 사이즈 설정
executor.setMaxPoolSize(10); // 최대 스레드 풀 사이즈 설정
executor.setThreadNamePrefix("multi_threaded_pool-");
executor.initialize();
return executor;
}
@Bean(name = "multiThreadedItemReader")
@StepScope
public JdbcPagingItemReader<EmployeeDto> multiThreadedItemReader() throws Exception {
return new JdbcPagingItemReaderBuilder<EmployeeDto>()
.name("multiThreadItemReader")
.dataSource(dataSource)
.pageSize(10000)
.fetchSize(10000)
.rowMapper(new BeanPropertyRowMapper<>(EmployeeDto.class))
.queryProvider(createQueryProvider())
.build();
}
public PagingQueryProvider createQueryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProviderFactoryBean = new SqlPagingQueryProviderFactoryBean();
queryProviderFactoryBean.setDataSource(dataSource);
queryProviderFactoryBean.setSelectClause("*");
queryProviderFactoryBean.setFromClause("from employee");
Map<String, Order> sortKeys = new HashMap<>(1);
sortKeys.put("employee_id", Order.ASCENDING);
queryProviderFactoryBean.setSortKeys(sortKeys);
return queryProviderFactoryBean.getObject();
}
@Bean(name = "multiThreadedItemProcessor")
@StepScope
public ItemProcessor<EmployeeDto, EmployeeDto> multiThreadedItemProcessor() {
return item -> {
item.setEmployeeName("Processed " + item.getEmployeeName());
return item;
};
}
@Bean(name = "multiThreadedItemWriter")
@StepScope
public ItemWriter<EmployeeDto> multiThreadedItemWriter() {
return new JdbcBatchItemWriterBuilder<EmployeeDto>()
.sql("INSERT INTO temp_employee (employee_id, begin_date, employee_name, end_date, employee_code, last_modified_date, created_date) " +
"VALUES (:employeeId, :beginDate, :employeeName, :endDate, :employeeCode, :lastModifiedDate, :createdDate)")
.dataSource(dataSource)
.beanMapped()
.build();
}
}- Multi-threaded Step의 경우, Single Thread 방식에서 TaskExecutor만 주입해주면 된다.
- 수행시간은 약 8초가 걸렸다. Single Thread 방식과 비교해서 약 2배가 빨라진 것을 확인할 수 있다.
- 총 10개의 thread로 병렬실행 했지만 결과는 2배 정도 빨라졌다.
Partitioning Step 코드 예시
Partitioning Step을 구성하기 위해서는 먼저 Partitioner를 구현해야 한다. 아래 코드는 Spring Batch Github를 참고했다.
RangePartitioner.java
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* Custom Partitioner
* <p>
* 데이터의 수를 체크해서 gridSize 만큼 ExecutionContext를 만듭니다.
*
*/
public class RangePartitioner implements Partitioner {
private JdbcTemplate jdbcTemplate;
private String table;
private String column;
public void setTable(String table) {
this.table = table;
}
public void setColumn(String column) {
this.column = column;
}
public void setDataSource(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
// 최소값과 최대값을 쿼리로 조회
Integer min = jdbcTemplate.queryForObject("SELECT MIN(" + column + ") from " + table, Integer.class);
Integer max = jdbcTemplate.queryForObject("SELECT MAX(" + column + ") from " + table, Integer.class);
if (min == null || max == null) {
throw new IllegalStateException("최소값 또는 최대값 쿼리 결과가 null입니다.");
}
// 타겟 사이즈 계산
int targetSize = (max - min) / gridSize + 1;
Map<String, ExecutionContext> result = new HashMap<>();
for (int i = 0, start = min; start <= max; i++, start += targetSize) {
ExecutionContext value = new ExecutionContext();
int end = start + targetSize - 1;
if (end > max) {
end = max;
}
value.putInt("minValue", start);
value.putInt("maxValue", end);
result.put("partition" + i, value);
}
return result;
}
}PartitioningJobConfiguration.java
import io.springbatch.example.common.batch.steps.chunk.itemReader.partitioner.RangePartitioner;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.PagingQueryProvider;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.database.builder.JdbcPagingItemReaderBuilder;
import org.springframework.batch.item.database.support.SqlPagingQueryProviderFactoryBean;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.TaskExecutor;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class PartitioningJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private final JdbcTemplate jdbcTemplate;
@Bean(name = "partitionJob")
public Job partitionJob() throws Exception {
return jobBuilderFactory.get("partitionJob")
.start(partitionedStep())
.listener(new JobExecutionListener() {
@Override
public void beforeJob(JobExecution jobExecution) {
jdbcTemplate.execute("TRUNCATE temp_employee;");
}
@Override
public void afterJob(JobExecution jobExecution) {
}
})
.build();
}
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); // 초기 스레드 풀 사이즈 설정
executor.setMaxPoolSize(10); // 최대 스레드 풀 사이즈 설정
executor.setThreadNamePrefix("partitioning_thread_pool-");
executor.initialize();
return executor;
}
@Bean
public Step partitionedStep() throws Exception {
return stepBuilderFactory.get("partitionedStep")
.partitioner(slaveStep().getName(), rangePartitioner())
.step(slaveStep())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
public Step slaveStep() throws Exception {
return stepBuilderFactory.get("slaveStep")
.<EmployeeDto, EmployeeDto>chunk(10000)
.reader(partitioningItemReader(null, null))
.processor(partitioningItemProcessor())
.writer(partitioningItemWriter())
.build();
}
@Bean(name = "customPartitioner")
public Partitioner rangePartitioner() {
RangePartitioner rangePartitioner = new RangePartitioner();
rangePartitioner.setColumn("employee_id");
rangePartitioner.setTable("employee");
rangePartitioner.setDataSource(dataSource);
return rangePartitioner;
}
@Bean(name = "partitioningItemReader")
@StepScope
public JdbcPagingItemReader<EmployeeDto> partitioningItemReader(
@Value("#{stepExecutionContext['minValue']}") Long minValue,
@Value("#{stepExecutionContext['maxValue']}") Long maxValue
) throws Exception {
return new JdbcPagingItemReaderBuilder<EmployeeDto>()
.name("multiThreadItemReader")
.dataSource(dataSource)
.pageSize(10000)
.fetchSize(10000)
.rowMapper(new BeanPropertyRowMapper<>(EmployeeDto.class))
.queryProvider(createQueryProvider(minValue, maxValue))
.build();
}
public PagingQueryProvider createQueryProvider(Long minValue, Long maxValue) throws Exception {
SqlPagingQueryProviderFactoryBean queryProviderFactoryBean = new SqlPagingQueryProviderFactoryBean();
queryProviderFactoryBean.setDataSource(dataSource);
queryProviderFactoryBean.setSelectClause("*");
queryProviderFactoryBean.setFromClause("from employee");
queryProviderFactoryBean.setWhereClause("where employee_id >= " + minValue + " and employee_id <= " + maxValue);
Map<String, Order> sortKeys = new HashMap<>(1);
sortKeys.put("employee_id", Order.ASCENDING);
queryProviderFactoryBean.setSortKeys(sortKeys);
return queryProviderFactoryBean.getObject();
}
@Bean(name = "partitioningItemProcessor")
@StepScope
public ItemProcessor<EmployeeDto, EmployeeDto> partitioningItemProcessor() {
return item -> {
item.setEmployeeName("Processed " + item.getEmployeeName());
return item;
};
}
@Bean(name = "partitioningItemWriter")
@StepScope
public ItemWriter<EmployeeDto> partitioningItemWriter() {
return new JdbcBatchItemWriterBuilder<EmployeeDto>()
.sql("INSERT INTO temp_employee (employee_id, begin_date, employee_name, end_date, employee_code, last_modified_date, created_date) " +
"VALUES (:employeeId, :beginDate, :employeeName, :endDate, :employeeCode, :lastModifiedDate, :createdDate)")
.dataSource(dataSource)
.beanMapped()
.build();
}
}- Step을 정의할 때에 복사할 Step의 Template과 Partitioner를 넣어주는 것을 확인할 수 있다.
- gridSize의 크기만큼 Step을 복사해서 실행한다고 보면 된다.
- 복사된 스탭은 각각 독립적인 스레드가 실행하는데 해당 스레드풀에 대한 TaskExecutor를 설정해 준다.
- ItemReader를 보면 stepExecutionContext에서 minValue, maxValue를 전달받아서 그 크기만큼 데이터를 읽어오는 것을 확인할 수 있다.
- 실행 결과는 아래와 같다.

- 1개의 Job안에서 gridSize만큼 Step이 복사되어서 실행되는 것을 확인할 수 있다. (정확히는 StepExecution이 여러 개 생성)
- 또한 batch_step_execution 테이블에도 gridSize만큼 StepExecution이 생성된 것을 확인할 수 있다.
- 수행시간은 6초 정도로 Single Thread와 Mulit-threaded 방식보다 더 빠른 것을 확인할 수 있다.
- 이 또한, 서버의 자원(CPU Core, Memory)에 따라서 결과는 달라질 수 있다.
References
'Spring Batch' 카테고리의 다른 글
| 대용량 작업 분산처리하기(With Spring Batch) (0) | 2023.06.04 |
|---|---|
| ExecutionContext (0) | 2022.04.02 |
| JobParameterValidator (0) | 2022.04.02 |
| Job, Step (0) | 2022.04.02 |
| Spring Batch 메타 테이블 (0) | 2022.04.02 |